redis进阶
Redis⽀持5种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
一、redis的常见使用场景
什么是Redis
Redis是由意⼤利⼈Salvatore Sanfilippo(⽹名:antirez)开发的⼀款内存⾼速缓存数据库。Redis全称为:Remote Dictionary
Server(远程数据服务),该软件使⽤C语⾔编写,Redis是⼀个key-value存储系统,它⽀持丰富的数据类型,如:string、list、set、zset(sorted set)、hash。
Redis特点
Redis以内存作为数据存储介质,所以读写数据的效率极⾼,远远超过数据库。以设置和获取⼀个256字节字符串为例,它的读取速度可⾼达110000次/s,写速度⾼达81000次/s。
Redis跟memcache不同的是,储存在Redis中的数据是持久化的,断电或重启后,数据也不会丢失。因为Redis的存储分为内存存储、磁盘存储和log⽂件三部分,重启后,Redis可以从磁盘重新将数据加载到内存中,这些可以通过配置⽂件对其进⾏配置,正因为这样,Redis 才能实现持久化。
Redis⽀持主从模式,可以配置集群,这样更利于⽀撑起⼤型的项⽬,这也是Redis的⼀⼤亮点。
Redis应⽤场景,它能做什么
众多语⾔都⽀持Redis,因为Redis交换数据快,所以在服务器中常⽤来存储⼀些需要频繁调取的数据,这样可以⼤⼤节省系统直接读取磁盘来获得数据的I/O开销,更重要的是可以极⼤提升速度。
拿⼤型⽹站来举个例⼦,⽐如a⽹站⾸页⼀天有100万⼈访问,其中有⼀个板块为推荐新闻。要是直接从数据库查询,那么⼀天就要多消耗100万次数据库请求。上⾯已经说过,Redis⽀持丰富的数据类型,所以这完全可以⽤Redis来完成,将这种热点数据存到Redis(内存)中,要⽤的时候,直接从内存取,极⼤的提⾼了速度和节约了服务器的开销。
总之,Redis的应⽤是⾮常⼴泛的,⽽且极有价值,真是服务器中的⼀件利器,所以从现在开始,我们就来⼀步步学好它。
【1】string&hash
点赞、踩、关注/被关注、共同好友等是社交网站的基本功能,社交网站的访问量通常来说比较大,而且传统的关系数据库类型不适合存储这种类型的数据,Redis提供的哈希、集合等数据结构能很方便的的实现这些功能。
案例1:计数器
什么是计数器,如电商网站商品的浏览量、视频网站视频的播放数等。为了保证数据实时效,每次浏览都得给+1,并发量高时如果每次都请求数据库操作无疑是种挑战和压力。Redis提供的incr命令来实现计数器功能,内存操作,性能非常好,非常适用于这些计数场景。
int类型,incr方法
例如:文章的阅读量、微博点赞数、允许一定的延迟,先写入Redis再定时同步到数据库
计数功能应该是最适合 Redis 的使用场景之一了,因为它高频率读写的特征可以完全发挥 Redis 作为内存数据库的高效。在 Redis 的数据结构中,string、hash和sorted set都提供了incr方法用于原子性的自增操作,下面举例说明一下它们各自的使用场景:
# 案例1
如果应用需要显示每天的注册用户数,便可以使用string作为计数器,设定一个名为REGISTERED_COUNT_TODAY的 key,并在初始化时给它设置一个到凌晨 0 点的过期时间,每当用户注册成功后便使用incr命令使该 key 增长 1,同时当每天凌晨 0 点后,这个计数器都会因为 key 过期使值清零。
# 案例2
每条微博都有点赞数、评论数、转发数和浏览数四条属性,这时用hash进行计数会更好,将该计数器的 key 设为weibo:weibo_id,hash的 field 为like_number、comment_number、forward_number和view_number,在对应操作后通过hincrby使hash 中的 field 自增。
# 案例3
以访问者的ip和其他信息作为key,访问一次增加一次计数,超过次数则返回false
案例2:购物车:
key:用户id;field:商品id;value:商品数量;
+1:hincr;
-1:hdecr;
删除:hincrby key field -1;
全选:hgetall;
商品数:hlen;
案例3: 连续七天在线用户
setbit firstday 0 1 //设置第一天uid是0的用户登录
setbit firstday 1 0 //设置第一天uid是1的用户未登录
setbit firstday 2 1 //设置第一天uid是2的用户登录
...
setbit secondday 0 0 //设置第二天uid是0的用户未登录
setbit secondday 1 1 //设置第二天uid是1的用户登录
setbit secondday 2 1 //设置第二天uid是2的用户登录... //以此类推
那么在算连续七天在线用户就是:
BITOP AND 7_both_online_users firstday secondday thirdday fourthday fifthday sixthday seventhday
还可以应用访问统计、在线用户统计等等。
【3】list
案例1
例如用户的消息列表、网站的公告列表、活动列表、博客的文章列表、评论列表等,通过 LRANGE 取出一页,按顺序显示。
案例2
显⽰最新的项⽬列表
下⾯这个语句常⽤来显⽰最新项⽬,随着数据多了,查询毫⽆疑问会越来越慢。
SELECT * FROM foo WHERE ... ORDER BY time DESC LIMIT 10
在Web应⽤中,“列出最新的回复”之类的查询⾮常普遍,这通常会带来可扩展性问题。这令⼈沮丧,因为项⽬本来就是按这个顺序被创建的,但要输出这个顺序却不得不进⾏排序操作。
类似的问题就可以⽤Redis来解决。⽐如说,我们的⼀个Web应⽤想要列出⽤户贴出的最新20条评论。在最新的评论边上我们有⼀个“显⽰全部”的链接,点击后就可以获得更多的评论。
我们假设数据库中的每条评论都有⼀个唯⼀的递增的ID字段。我们可以使⽤分页来制作主页和评论页,使⽤Redis的模板,每次新评论发表时,我们会将它的ID添加到⼀个Redis列表:
LPUSH latest.comments <ID>
我们将列表裁剪为指定长度,因此Redis只需要保存最新的5000条评论:
LTRIM latest.comments 0 5000
每次我们需要获取最新评论的项⽬范围时,我们调⽤⼀个函数来完成(使⽤伪代码):
FUNCTION get_latest_comments(start, num_items):
id_list = redis.lrange("latest.comments",start,start+num_items - 1)
IF id_list.length < num_items
id_list = SQL_DB("SELECT ... ORDER BY time LIMIT ...")
END
RETURN id_list
END
这⾥我们做的很简单。在Redis中我们的最新ID使⽤了常驻缓存,这是⼀直更新的。但是我们做了限制不能超过5000个ID,因此我们的获取ID函数会⼀直询问Redis。只有在start/count参数超出了这个范围的时候,才需要去访问数据库。我们的系统不会像传统⽅式那样“刷新”缓存,Redis实例中的信息永远是⼀致的。SQL数据库(或是硬盘上的其他类型数据库)只是在⽤户需要获取“很远”的数据时才会被触发,⽽主页或第⼀个评论页是不会⿇烦到硬盘上的数据库了。
【4】集合(set)
1. 商品筛选
案例1

华为P40上线了,支持民族品牌,加到各个标签中去。
sadd brand:huawei p40
sadd os:android p40
sadd screensize:6.0-6.24 p40
买的时候筛选,牌子是华为,操作系统是安卓,屏幕大小在6.0-6.24之间的,取交集:
sinter brand:huawei os:android screensize:6.0-6.24
案例2

# 我们以微博举例子,假设这条微博的ID是t1001,用户ID是u6001,
用dianzan:t1001来维护t1001这条微博的所有点赞用户。
点赞了这条微博:sadd dianzan:t1001 u6001
取消点赞:srem dianzan:t1001 u6001
是否点赞:sismember dianzan:t1001 u6001
点赞的所有用户:smembers dianzan:t1001
点赞数:scard dianzan:t1001
案例3:特定时间内的特定项⽬
另⼀项对于其他数据库很难,但Redis做起来却轻⽽易举的事就是统计在某段特点时间⾥有多少特定⽤户访问了某个特定资源。⽐如我想要知道某些特定的注册⽤户或IP地址,他们到底有多少访问了某篇⽂章。
每次我获得⼀次新的页⾯浏览时我只需要这样做:
SADD page:day1:<page_id> <user_id>
想知道特定⽤户的数量吗?只需要使⽤
SCARD page:day1:<page_id>
需要测试某个特定⽤户是否访问了这个页⾯?
SISMEMBER page:day1:<page_id>
【5】有序集合(Zset)
很多网站都有排行榜应用的,如京东的月度销量榜单、商品按时间的上新排行榜等。Redis提供的有序集合数据类构能实现各种复杂的排行榜应用。
案例1
如果应用有一个发帖排行榜的功能,便选择sorted set吧,将集合的 key 设为POST_RANK。当用户发帖后,使用zincrby将该用户 id 的 score 增长 1。sorted set会重新进行排序,用户所在排行榜的位置也就会得到实时的更新。
案例2
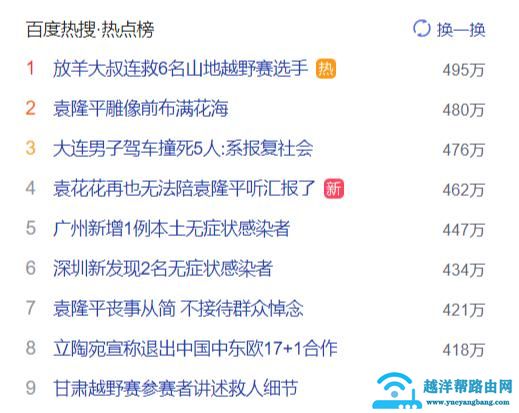
今天是2021年5月23号,建一个 key 为 hotSearch:20210523 的 zset。
放羊大叔这条新闻的id是n1234,每点击一下:zincrby hotSearch:20210523 1 n1234
获取热搜排行榜前十条:zrevrange hotSearch:20210523 0 10 withscores
袁老国士无双,一路走好,中华民族的儿女不会忘记您!
案例3:延迟队列
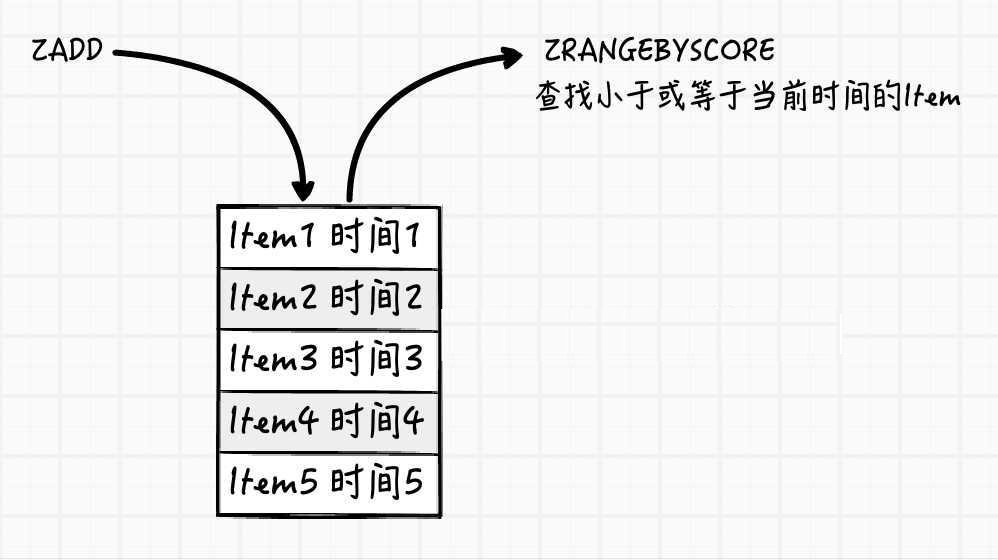
延时队列可以通过Redis的zset(有序列表)来实现。我们将消息序列化为一个字符串作为zset的值。这个消息的到期时间处理时间作为score,然后用多个线程轮询zset获取到期的任务进行处理,多线程时为了保障可用性,万一挂了一个线程还有其他线程可以继续处理。因为有多个线程,所有需要考虑并发争抢任务,确保任务不能被多次执行。
import time
import uuid
import redis
pool = redis.ConnectionPool(host='127.0.0.1', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
def delay_task(task_name, delay_time):
# 保证value唯一
task_id = task_name + str(uuid.uuid4())
retry_ts = time.time() + delay_time
r.zadd("delay-queue", {task_id: retry_ts})
def loop():
print("循环监听中...")
while True:
# 最多取1条
task_list = r.zrangebyscore("delay-queue", 0, time.time(), start=0, num=1)
if not task_list:
# 延时队列空的,休息1s
print("cost 1秒钟")
time.sleep(1)
continue
task_id = task_list[0]
success = r.zrem("delay-queue", task_id)
if success:
# 处理消息逻辑函数
handle_msg(task_id)
def handle_msg(msg):
"""消息处理逻辑"""
print(f"消息{msg}已经被处理完成!")
import threading
t = threading.Thread(target=loop)
t.start()
delay_task("任务1延迟5", 5)
delay_task("任务2延迟2", 2)
delay_task("任务3延迟3", 3)
delay_task("任务4延迟10", 10)
redis的zrem方法是对多线程争抢任务的关键,它的返回值决定了当前实例有没有抢到任务,因为loop方法可能会被多个线程、多个进程调用, 同一个任务可能会被多个进程线程抢到,通过zrem来决定唯一的属主。同时,一定要对handle_msg进行异常捕获, 避免因为个别任务处理问题导致的循环异常退出。
【6】分布式
(1)分布式会话
集群模式下,在应用不多的情况下一般使用容器自带的session复制功能就能满足,当应用增多相对复杂的系统中,一般都会搭建以Redis等内存数据库为中心的session服务,session不再由容器管理,而是由session服务及内存数据库管理。
(2)分布式锁
在很多互联网公司中都使用了分布式技术,分布式技术带来的技术挑战是对同一个资源的并发访问,如全局ID、减库存、秒杀等场景,并发量不大的场景可以使用数据库的悲观锁、乐观锁来实现,但在并发量高的场合中,利用数据库锁来控制资源的并发访问是不太理想的,大大影响了数据库的性能。可以利用Redis的setnx功能来编写分布式的锁,如果设置返回1说明获取锁成功,否则获取锁失败,实际应用中要考虑的细节要更多。
什么是分布式锁
分布式锁其实就是,控制分布式系统不同进程共同访问共享资源的一种锁的实现。如果不同的系统或同一个系统的不同主机之间共享了某个临界资源,往往需要互斥来防止彼此干扰,以保证一致性。
提到Redis的分布式锁,很多小伙伴马上就会想到setnx+ expire命令。即先用setnx来抢锁,如果抢到之后,再用expire给锁设置一个过期时间,防止锁忘记了释放。
SETNX 是SET IF NOT EXISTS的简写.日常命令格式是SETNX key value,如果 key不存在,则SETNX成功返回1,如果这个key已经存在了,则返回0。
假设某电商网站的某商品做秒杀活动,key可以设置为key_resource_id,value设置任意值,伪代码如下:
方案1
import redis
pool = redis.ConnectionPool(host='127.0.0.1')
r = redis.Redis(connection_pool=pool)
ret = r.setnx("key_resource_id", "ok")
if ret:
r.expire("key_resource_id", 5) # 设置过期时间
print("抢购成功!")
r.delete("key_resource_id") # 释放资源
else:
print("抢购失败!")
但是这个方案中,setnx和expire两个命令分开了,「不是原子操作」。如果执行完setnx加锁,正要执行expire设置过期时间时,进程crash或者要重启维护了,那么这个锁就“长生不老”了,「别的线程永远获取不到锁啦」。
方案2
SETNX + value值是(系统时间+过期时间)
为了解决方案一,「发生异常锁得不到释放的场景」,可以把过期时间放到setnx的value值里面。如果加锁失败,再拿出value值校验一下即可。加锁代码如下:
import time
def foo():
expiresTime = time.time() + 10
ret = r.setnx("key_resource_id", expiresTime)
if ret:
print("当前锁不存在,加锁成功")
return True
oldExpiresTime = r.get("key_resource_id")
if float(oldExpiresTime) < time.time(): # 如果获取到的过期时间,小于系统当前时间,表示已经过期
# 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间
newExpiresTime = r.getset("key_resource_id", expiresTime)
if oldExpiresTime == newExpiresTime:
# 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才可以加锁
return True # 加锁成功
return False # 其余情况加锁皆失败
foo()
方案3
实际上,我们还可以使用Py的redis模块中的set函数来保证原子性(包含setnx和expire两条指令)代码如下:
r.set("key_resource_id", "1", nx=True, ex=10)
【7】发布订阅
subscribe channel # 订阅
publish channel mes # 发布消息
import threading
import redis
r = redis.Redis(host='127.0.0.1')
def recv_msg():
pub = r.pubsub()
pub.subscribe("fm104.5")
pub.parse_response()
while 1:
msg = pub.parse_response()
print(msg)
def send_msg():
msg = input(">>>")
r.publish("fm104.5", msg)
t = threading.Thread(target=send_msg)
t.start()
recv_msg()
定时任务:利用 Redis 也能实现订单30分钟自动取消。
用户下单之后,在规定时间内如果不完成付款,订单自动取消,并且释放库存使用技术:Redis键空间通知(过期回调)用户下单之后将订单id作为key,任意值作为值存入redis中,给这条数据设置过期时间,也就是订单超时的时间启用键空间通知
# 开启过期key监听
from redis import StrictRedis
redis = StrictRedis(host='localhost', port=6379)
# 监听所有事件
# pubsub = redis.pubsub()
# pubsub.psubscribe('__keyspace@0__:*')
#
# print('Starting message loop')
# while True:
# message = pubsub.get_message()
# if message:
# print(message)
# 监听过期key
def event_handler(msg):
print("sss",msg)
thread.stop()
pubsub = redis.pubsub()
pubsub.psubscribe(**{'__keyevent@0__:expired': event_handler})
thread = pubsub.run_in_thread(sleep_time=0.01)
现代的互联⽹应⽤⼤量地使⽤了消息队列(Messaging)。消息队列不仅被⽤于系统内部组件之间的通信,同时也被⽤于系统跟其它服务之间的交互。消息队列的使⽤可以增加系统的可扩展性、灵活性和⽤户体验。⾮基于消息队列的系统,其运⾏速度取决于系统中最慢的组件的速度(注:短板效应)。⽽基于消息队列可以将系统中各组件解除耦合,这样系统就不再受最慢组件的束缚,各组件可以异步运⾏从⽽得以更快的速度完成各⾃的⼯作。
消息队列是大型网站必用中间件,如ActiveMQ、RabbitMQ、Kafka等流行的消息队列中间件,主要用于业务解耦、流量削峰及异步处理实时性低的业务。Redis提供了发布/订阅及阻塞队列功能,能实现一个简单的消息队列系统。另外,这个不能和专业的消息中间件相比。
Redis 是目前 NoSQL 领域的当红炸子鸡,它象一把瑞士军刀,小巧、锋利、实用,特别适合解决一些使用传统关系数据库难以解决的问题。但是 Redis 不是银弹,有很多适合它解决的问题,但是也有很多并不适合它解决的问题。另外,Redis 作为内存数据库,如果用在不适合的场合,对内存的消耗是很可观的,甚至会让系统难以承受。
我们可以对系统存储使用的数据以两种角度分类,一种是按数据的大小划分,分成大数据和小数据,另一种是按数据的冷热程度划分,分成冷数据和热数据,热数据是指读或写比较频繁的数据,反之则是冷数据。
可以举一些具体的例子来说明数据的大小和冷热属性。比如网站总的注册用户数,这明显是一个小而热的数据,小是因为这个数据只有一个值,热是因为注册用户数随时间变化很频繁。再比如,用户最新访问时间数据,这是一个量比较大,冷热不均的数据,大是数据的粒度是用户级别,每一个用户都有数据,如果有一千万用户,就意味着有一千万的数据,冷热不均是因为活跃用户的最新访问时间变化很频繁,但是可能有很大一部非活跃用户访问时间长时间不会发生变化。
大体而言,Redis 最适合处理的是小而热,而且是写频繁,或者读写都比较频繁的热数据。对于大而热的数据,如果其它方式很难解决问题,也可以考虑使用 Redis 解决,但是一定要非常谨慎,防止数据无限膨胀。原因如下:
首先,对于冷数据,无论大小,都不建议放在 Redis 中。Redis 数据要全部放在内存中,资源宝贵,把冷数据放在其中实在是一种浪费,冷数据放在普通的存储比如关系数据库中就好了。
其次,对于热数据,尤其是写频繁的热数据,如果量比较小,是最适合放到 Redis 中的。比如上面提到的网站总的注册用户数,就是典型的 Redis 用做计数器的例子。再比如论坛最新发表列表,最新报名列表,可以控制数量在几百到一千的规模,也是典型的 redis 做最新列表的使用方式。
另外,对于量比较大的热数据(或者冷热不均数据),使用 Redis 时一定要比较谨慎。这种类型数据很容易引起数据膨胀,导致 Redis 消耗内存巨大,让系统难以承受。薄荷的一个惨痛教训是把用户关注(以及被关注)数据放在 Redis 中,这是一种数据量极大,冷热很不均衡的数据,在几百万的用户级别就占用了近 10 GB左右内存,让 Redis 变得难以应付。应对这种类型的数据,可以用普通存储 + 缓存的方式。
如果用对了地方,比如在小而热的数据情形,Redis 表现很棒,如果用错了地方,Redis 也会带来昂贵的代价,所以使用时务必谨慎。